- Published on
Use Shared Lower Environments
- Authors
- Name
- Sedky Haider


Why do developers need to run a whole stack in order to contribute to development? Why do they need to run & seed a database in order to make changes to an API? Why do they need to run APIs when making changes only to front-ends?
We don't. This is the power of shared environments.
We're going to use an app that lets you purchase & sell equities through broker APIs. In a modern microservices world, this could include:
• Frontend for the end users
• User API which stores user data
• Database such as #postgres or #mongodb
• Transactions API to facilitate payment through Stripe , Plaid , similar, and purchase equity from some broker such as Alpaca
• Notification API to send notifications to customers such as Twilio
I've deployed the dev environment here for fun.
Let's look at the architecture:

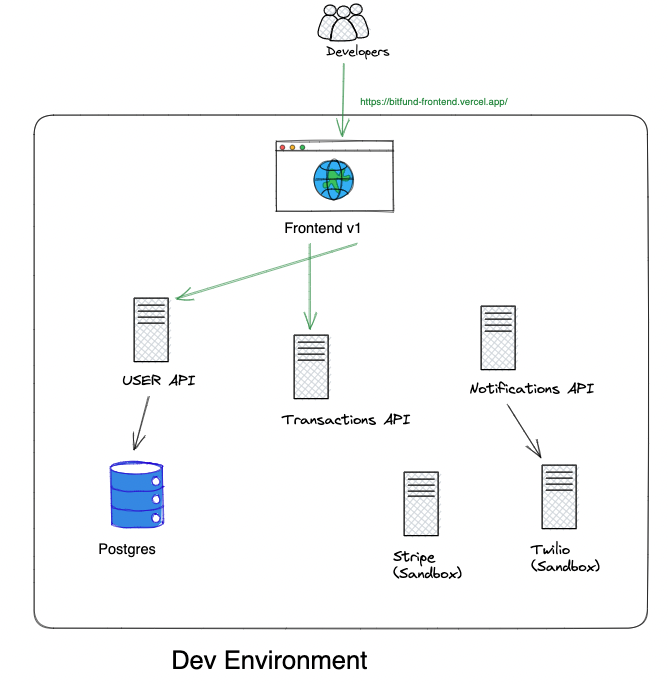
The dev config is driven by a simple .env file, so we can by default point all the dev services at each other.
So let's say we want to make a front-end change.

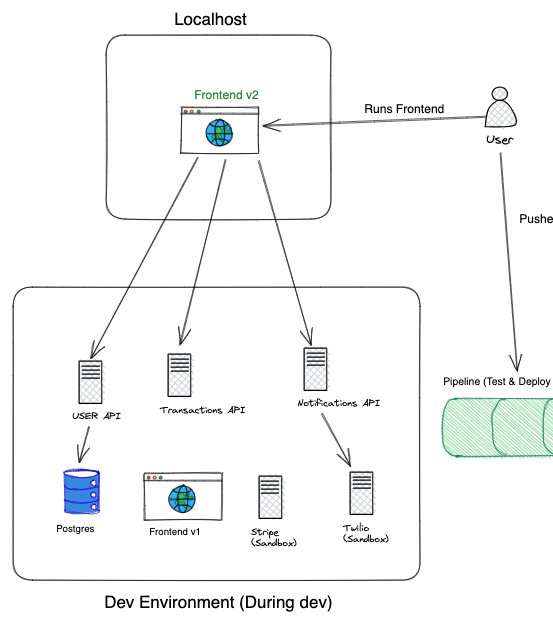
- The Developer runs
git cloneof the front-end code - Runs
npm i&&npm run dev.
That's it.. now we have a front-end running on http://localhost:3000 which is connecting to all the above services which are already running in our shared environment.
🤯🤯🤯
When they are happy with their changes:
- the developers creates a PR
- This kicks off automated tests (the CI process)
- Once the changes are merged into
master, this kicks off the deployment (CD) process

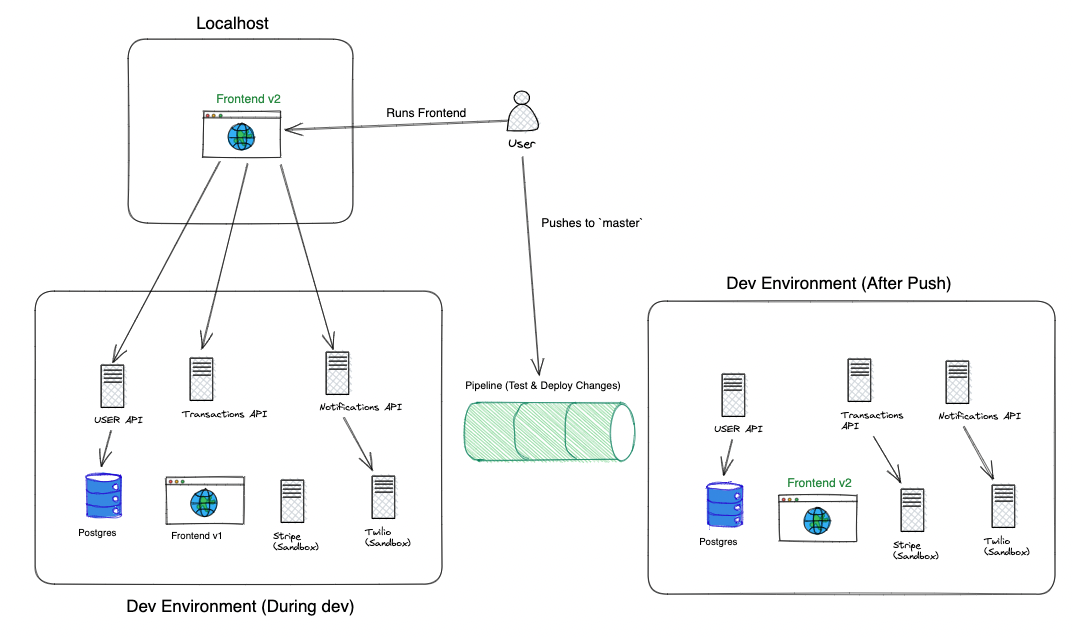
Pushing to Production
Pushing to production is the easiest step of them all as the hard work is done. Our code has been automatically tested, and can even undergo manual testing in our shared environment.
This is where things like "stageless" environments can start to go away.
We shouldn't need to do any additional testing of any kind because we've already done that during our CI process.

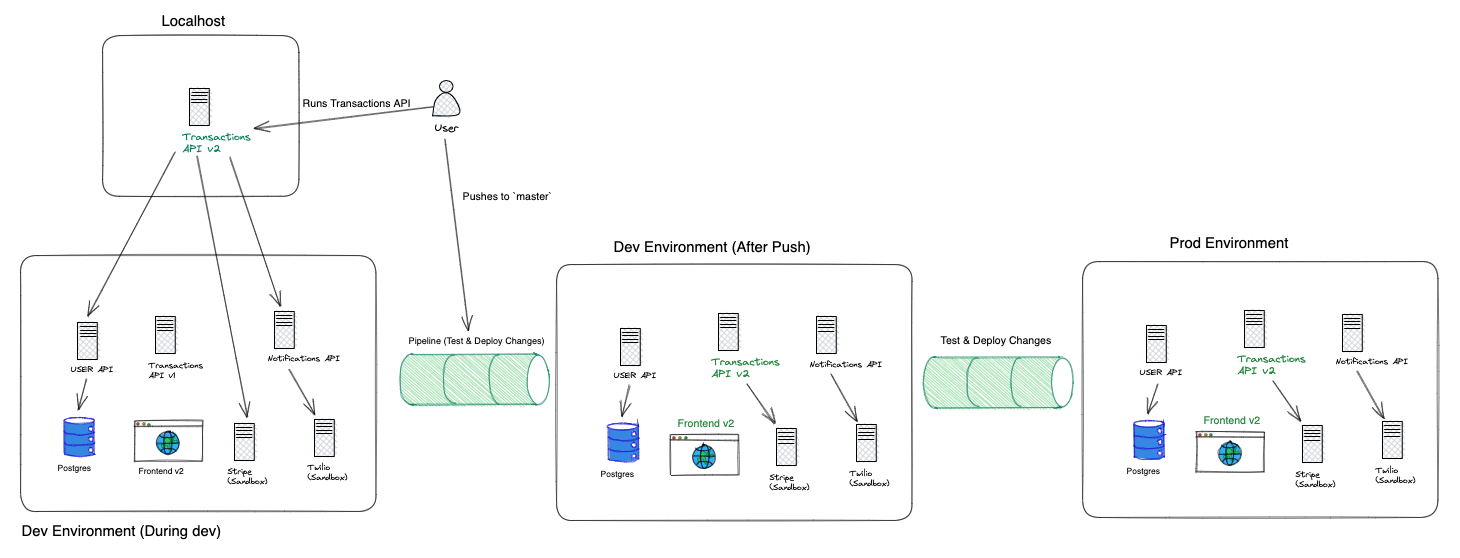
Our release process is as complicated as we want it to be.
If we're delivering self-managed software, then we need to release the code in a way that's consumable by operators, using semantic versioning. How often you do that is a balance between your release speed and how much you cognitive overhead you introduce to your customers.
However, if our software is a SaaS, we can deliver our code as many times as you want. In fact, there's loads of industry thought that suggests the more you push, the less risk is introduced. In other words, we can go right from lower environment to production! This keeps our development environment mirroring production as closely as possible whilst giving us the obvious benefits associated with Continous Delivery.
Requirements To Pull off
• Ability to quickly revert/deploy microservices - a given. We are now very reliant on our CI pipeline. It better be rock-solid.
• Zero-downtime schema migrations. Database changes can affect all developers. This is one area that PlanetScale 's database schema branching[0] attempts to solve. Alternatively, zero downtime schema migrations are enabled by making schemas backwards compatible so you can quickly revert
• Extreme confidence in unit testing. If you're pushing changes to a shared dev environment, having wide automated testing will limit the damage and downtime you cause to other developers and services
• Observability & Telemetry. Debugging becomes much harder in this model. When your trace is failing in some upstream microservice that you can't set a breakpoint in, you are now at the mercy of whatever log aggregation platform you're using.
• A large upfront investment in making services available to developers in a secure manner. Are my services traversing the internet? Am I using an #apigateway ?
Alternatives:
Instead of an always-online shared lower environment, we can look at loft.sh or Gitpod, but I personally don't have experience with these.
Do you use shared lower environments? Is this something possible at scale, even as little as tens of services? Send me an email or talk to me on LinkedIn, I'd love to hear more about it!